By Mark Buraga, Independent SEO Consultant at Growth Engine PH
Most boutique firms have schema markup deployed. Almost none have it deployed in a way AI engines can use. Both situations look identical from the outside. They produce opposite outcomes in AI search. Schema’s the only thing in SEO where “we have it” and “we have it” can mean two completely different things – like asking two people if they have a relationship.
Here’s what changed underneath the conversation. Schema markup stopped being about rich snippets in Google results and quietly became the parseability layer AI engines use to verify authority. Most firms either have schema auto-generated by a plugin that says nothing useful, or no schema at all. To an AI engine, those are the same page: one it cannot parse, from a firm it cannot verify. The fix is small, technical, and almost always already inside the existing SEO retainer. Most agencies are not making it.
Why “Do We Have Schema?” Is the Wrong Question

Most boutique firms have schema markup technically deployed; almost none have it deployed in a form AI engines can use to verify authority, and the two situations look identical from the outside.
The first question a partner or marketing director asks their SEO vendor about structured data is “do we have schema markup?” The answer is almost always yes. The conversation ends there. The page validates in Google’s Rich Results Test, the technical box gets ticked, the line item gets billed. The firm has schema.
What the firm actually has is a Yoast, Rank Math, or Schema Pro plugin generating a default Article block. It declares the page is an Article and the publisher is the website, and then it stops. No author Person. No Organization detail. No credentials. No sameAs links to anywhere AI can verify. The markup is present and the firm is still invisible to the systems that increasingly decide who gets cited in a synthesized answer.
The question that actually separates the two groups, and the one almost nobody runs on their agency, is this: what does AI see when it reads our schema, and does that match what we say we are? Firms whose schema does real work can answer it. Firms whose schema is decorative cannot. Most boutique practices are in the second group and do not know it.
What Schema Markup Actually Is (In Two Paragraphs, Without Code)

Schema markup is a block of structured data inside your page’s HTML that declares to machines what the page is, who wrote it, what organization published it, and which external sources can verify the claim.
A web page has two layers. There’s the rendered text a human reads, and there’s the structured data a machine reads. Schema markup is the second layer. It sits in the page’s HTML as a JSON-LD script block: invisible to a browsing reader, fully visible to any search engine, AI engine, or other automated consumer of the page.
Think of it as a contract between the publisher and the machine reader. The publisher declares: this page is an Article, written by this Person, who works at this Organization, with these credentials, and here are external URLs you can check to verify any of it. The machine reader can take the declaration on trust or test it against the cross-references. Either way the page becomes legible to systems that would otherwise have to infer everything from prose. Good schema makes the engine’s job easy. Missing schema makes the engine guess, and engines that guess move on to a source that does not make them.
The Shift From Rich Snippets to AI Parseability
Schema markup originated as a way to win rich snippets in Google results; in 2026, its load-bearing function is parseability for AI engines that decide which firms get cited in synthesized answers.
For a decade, schema markup was an SEO tactic with visible payoffs: rich snippets, knowledge panels, breadcrumb displays, FAQ accordions. That use case has not gone anywhere. Google still renders rich results for pages with valid schema. But that is no longer the part doing the heavy lifting.
AI engines (Google AI Overviews, ChatGPT, Perplexity, Claude) consume the open web at scale. When one of them parses a page to decide whether to cite it, it reads the rendered text and it reads the JSON-LD block. The JSON-LD is what tells the engine this is an article, by this named author, at this organization, with these credentials. Strip that block and the engine has to reconstruct all of it from prose, which is slow, error-prone, and frequently wrong. A firm with a complete schema stack makes the engine’s job tractable. A firm without one asks the engine to do extra work, then loses the citation to a competitor that already declared itself plainly.
“Schema doesn’t impact rankings” is still true for Google’s classic ten-blue-links result. It is also beside the point. The decision that matters now is AI citation, and AI citation runs on parseability.
The Seven Schema Types That Matter for Boutique Professional Services
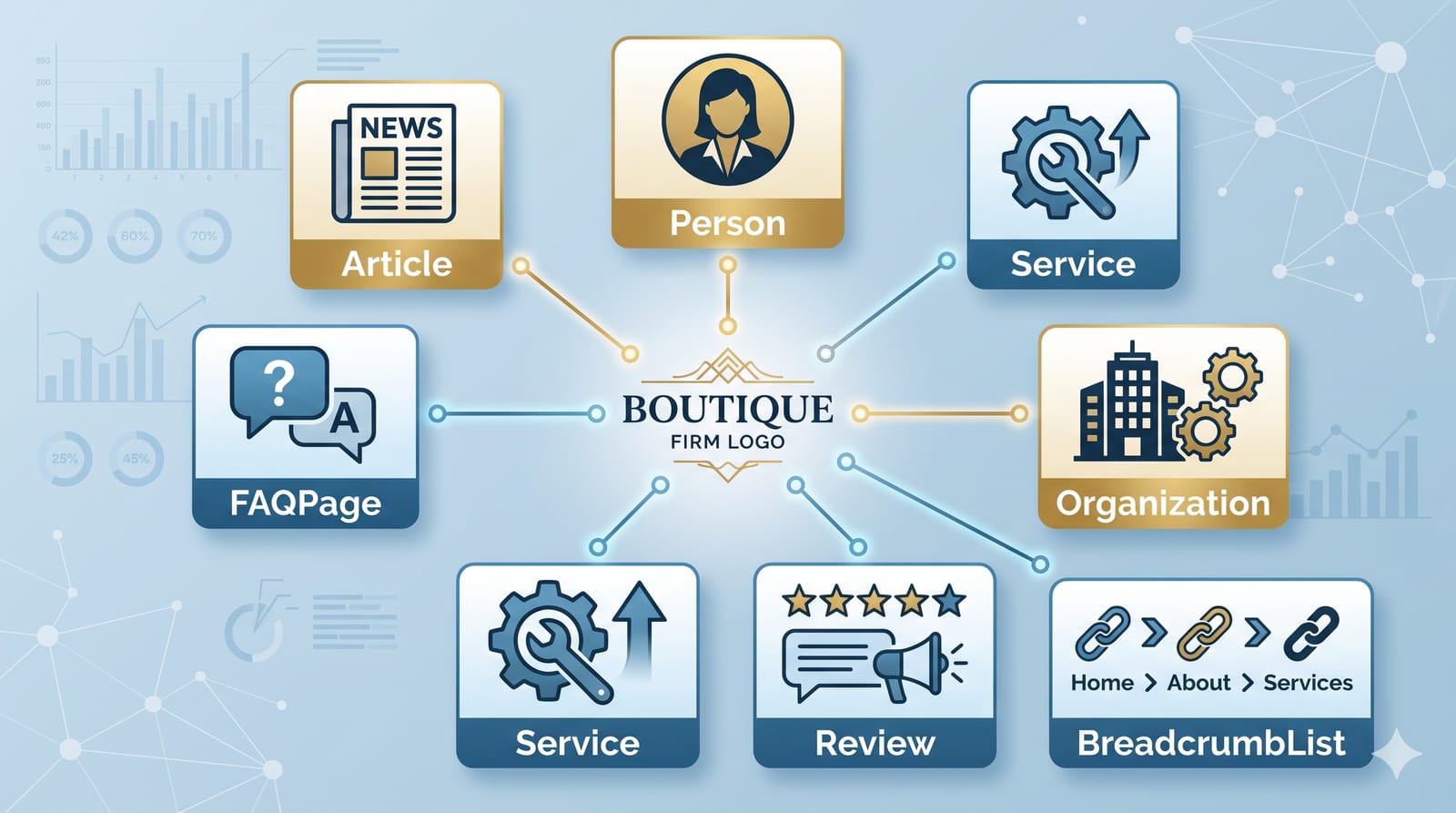
Of Schema.org’s 800+ types, seven cover the parseability needs of every boutique professional services firm: Article, FAQPage, Organization (or LocalBusiness), Person, Service, Review, and BreadcrumbList.
Schema.org’s full vocabulary runs past 800 types, covering everything from 3D models to dataset metadata to recipe nutrition labels. Almost none of it is relevant to a boutique law, accounting, or advisory practice. Seven types do the load-bearing work. Deploy these correctly and the AI-parseability layer is solid. Skip them and no volume of content production fills the gap.
Article schema (with named author Person)
Article schema with a named author Person and dateModified is the minimum AI engines need to recognize a blog post as authored content from a credentialed source.
Every blog post should declare itself an Article, with the author nested as a Person object carrying name, jobTitle, worksFor, and sameAs links to professional profiles. The dateModified field matters as much as datePublished. AI engines weight recency, and a 2020 post with no modification date reads as stale even after the content has been quietly updated. The publisher is the Organization, not the website. The author is a Person with credentials, not a string.
FAQPage schema
FAQPage schema lets you declare reader questions and your answers in machine-readable form, which AI engines extract directly into Overviews and chat responses.
If a page shows readers an FAQ section, the same questions and answers belong in FAQPage schema. AI engines lift FAQPage entries straight into AI Overview answers and ChatGPT responses when the user’s query matches the question. Two rules govern this. The schema questions must match the visible page questions verbatim, with no rewriting. And the answers must not be padded with marketing copy that never appears on the visible page. Both shortcuts get caught.
Organization (or LocalBusiness) schema
Organization schema with full legal name, address, and sameAs links is how AI engines verify your firm against external authority sources like bar associations, accounting registries, and professional indexes.
Every page should reference the firm as an Organization: full legal name, registered alternate name where it applies, address, and the field that carries the weight, sameAs. SameAs is an array of URLs pointing to external profiles AI can cross-reference. For a law firm, that means the bar association directory entry, the LinkedIn company page, and any recognized professional index. For an accounting practice, the equivalent: the relevant professional body listing (AICPA, PICPA, ACCA, ICAEW), the LinkedIn page, regulatory registry entries. A single-office firm with a public address uses the LocalBusiness variant. Multi-office firms typically use the broader Organization type.
Person schema (for partners and named authors)
Person schema with credentials, professional title, and sameAs links to bar or professional-body profiles is how AI verifies the named author of a page is a credible practitioner.
Each partner, principal, or named author who appears on a page should be declared as a Person with name, jobTitle, worksFor, and sameAs links to their professional profiles. For lawyers: bar association profile, LinkedIn personal profile, professional body listing. For accountants: AICPA or CPA registration, LinkedIn, regulatory profile. For consultants: published methodology profiles, LinkedIn, recognized industry directories. The sameAs is the verification path. AI engines follow those URLs to confirm the named person is who the page claims they are.
Service, Review, and BreadcrumbList (the supporting cast)
Service schema declares what you do, Review schema declares third-party validation, and BreadcrumbList declares site structure – three secondary types AI uses to round out its model of your firm.
Service schema is the right type for each distinct practice area, declared with name, description, and provider (the Organization). Review schema declares third-party validation when a client testimonial or review is published with attribution. The rules around Review schema are strict, and faking reviews triggers manual penalties, so deploy it only where the underlying review is real and attributable. BreadcrumbList schema declares site hierarchy and helps AI engines place a page inside the firm’s broader content structure. These three sit behind the first four. Skipping them does not break anything; it leaves AI’s model of the firm a little blurrier than it needs to be.
What Bad Schema Looks Like (And Why Plugin Defaults Are Bad Schema)

A WordPress plugin’s default Article schema declares the page is an Article and the publisher is the website, and stops there – which is technically valid and functionally useless for AI verification.
Here is a Yoast-default Article schema, the kind running on a boutique professional services blog post right now:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Schema Markup for AI Search Visibility",
"datePublished": "2026-05-22",
"publisher": {
"@type": "Organization",
"name": "Growth Engine PH"
}
}This validates fine. It is also useless. It says the page is an Article and the publisher is the website, and tells AI engines nothing about who wrote it, what credentials they hold, what external sources verify any of it, or how the page connects to the firm’s identity. Almost every boutique professional services site has exactly this deployed and counts the schema box ticked.
The 30-second self-diagnostic: paste your homepage URL into Google’s Rich Results Test (search.google.com/test/rich-results) and read the Detected items output. If the Organization block has no sameAs array, or the Article block has no author Person nested with credentials and sameAs, the schema is plugin-default. Present in the page source, absent from anything AI can act on.
What Good Schema Looks Like (Worked Example for a Boutique Firm)

A complete AI-ready schema stack for a boutique firm’s blog post includes Article + Person + Organization, with sameAs cross-references to at least two external credibility sources for both the author and the firm.
Here is the same blog post with a schema stack AI engines can actually use:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Schema Markup for AI Search Visibility: What Boutique Firms Are Missing",
"datePublished": "2026-05-22",
"dateModified": "2026-05-22",
"author": {
"@type": "Person",
"name": "Mark Buraga",
"jobTitle": "Independent SEO Consultant",
"worksFor": {
"@type": "Organization",
"name": "Growth Engine PH",
"url": "https://growthengineph.com"
},
"sameAs": [
"https://www.linkedin.com/in/markburaga/",
"https://growthengineph.com/about/"
]
},
"publisher": {
"@type": "Organization",
"name": "Growth Engine PH",
"url": "https://growthengineph.com",
"logo": {
"@type": "ImageObject",
"url": "https://growthengineph.com/logo.png"
},
"sameAs": [
"https://www.linkedin.com/company/growthengineph/"
]
},
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://growthengineph.com/blog/schema-markup-ai-search-visibility/"
}
}Same article, declared in full. An AI engine reading this knows who wrote it, their job title, where they work, and has two sameAs URLs to confirm the author exists. It knows the publisher is an Organization with its own URL, logo, and LinkedIn company page to cross-reference. The verification cascade has somewhere to land instead of dead-ending in prose.
The pattern holds across verticals. For a boutique law firm, the partner’s Person block should sameAs to their state or jurisdiction bar association directory, their LinkedIn personal page, and any professional body listing. For an accounting practice: the AICPA, PICPA, ACCA, or ICAEW directory, LinkedIn, and the relevant regulatory body. For an advisory consultancy: the published methodology profile, LinkedIn, and any recognized industry index. Declare the named expert with credentials, then hand AI the cross-references it needs to verify them.
How to Audit Your Current Schema (30 Minutes, No Developer Required)

A boutique schema audit consists of running Google’s Rich Results Test on your homepage, your services page, and three recent blog posts, then comparing what AI sees against what your firm actually is.
The audit is mechanical. Pick the five pages that matter most: the homepage, the about page, the primary services or practice-area page, and two or three of the most recent blog posts. Paste each URL into Google’s Rich Results Test. Read the Detected items. For each detected item, ask three questions:
- Does it declare the firm by name? The Organization or LocalBusiness block must carry the full legal name, the alternate name if one is used, and the registered address.
- Does it name the author? Article schema must carry an author Person object with name, jobTitle, worksFor, and sameAs links to at least one external profile.
- Does it sameAs to anything verifiable? Both the Organization and the Person should carry sameAs arrays pointing to LinkedIn, professional body directories, regulatory registries, or other credible external sources.
A “no” to any of the three means the schema is incomplete on that page. A “no” to all three means it is plugin-default, and the firm is invisible to AI verification on that page template.
How to Fix It (Decision Tree by Site Type)
For most boutique firms on WordPress, schema reconciliation is a plugin configuration change plus three custom fields, completed in one afternoon; for custom-built sites, it is a one-time developer task scoped at 4-8 hours.
WordPress + Yoast SEO. Yoast deploys the core schema types out of the box, but the editorial fields ship blank. Complete the Organization profile in Yoast’s Site Representation settings: full legal name, alternate name, address, logo URL. Add the Other profiles section pointing to LinkedIn, professional body directories, and regulatory registries. Set the Site Representation type to Organization, or Person if it is a solo practitioner with no Organization layer. Then, for each author on the site, fill in the WordPress user profile with name, bio, role, and the sameAs URLs. Yoast picks these up and injects the correct Person block into Article schema automatically. One afternoon for a clean deployment.
WordPress + Rank Math. The equivalent fields live under Titles & Meta and General settings. The work is identical: complete the Organization fields, add the social profiles array, deploy Person schema for each author with full credentials and sameAs.
WordPress + Schema Pro or custom JSON-LD. Schema Pro generates JSON-LD through a separate configuration layer; the same editorial work applies. Sites already running custom JSON-LD usually have the structure in place but the values half-filled. The audit shows which fields are missing; a developer or the agency editorial team fills them in.
Custom-built site (non-WordPress). The schema is hand-coded. The fix is a one-time scope, typically 4-8 hours to extend the existing schema templates with the missing fields: sameAs, complete author Person blocks, complete Organization block. After that one fix, every new page generates correctly.
In every route, the part that cannot be automated is the editorial decision: which credentials to declare, which sameAs URLs to include, which Person authored which post. That is configuration, not code. A competent SEO retainer should be doing it inside standard scope. If yours is not, the question worth asking is why.
What Happens After You Fix It
Within 30-90 days of deploying accurate schema with sameAs cross-references, most firms begin showing up in AI engine answers for priority practice-area queries; the lift is slower than a Google ranking change and more durable.
The timeline is asymmetric. A Google ranking change can land inside a crawl cycle, days to weeks. An AI citation change lags: AI engines re-evaluate their citation sources on slower cycles, so a newly-correct schema deployment tends to surface in AI answers 30 to 90 days later. Slower going in, but more durable once it arrives, because schema gains reflect actual identity rather than a gameable signal. Once AI engines can parse the firm, they keep being able to. The deployment compounds.
What to watch across those 30 to 90 days: run manual prompt tests in ChatGPT, Perplexity, and Google AI Overviews for the firm’s priority practice-area queries. Note which answers cite the firm, which cite a directory aggregator, and which cite a competitor. The firms holding the highest citation share at 90 days are the ones with the cleanest schema, the most complete sameAs cross-references, and the most consistent entity declarations across pages. The firms still on plugin defaults stay out of the answer entirely.
What’s Next: From Plugin Defaults to AI Parseability
The shift is structural, not cosmetic. Schema started as a way to enrich Google results and became the parseability layer AI engines use to verify firms. That transition ran over roughly the last 18 months, and most boutique professional services firms did not register it. Their agency confirmed schema was deployed. The plugin generated the markup. The Rich Results Test validated. The box got ticked. None of those steps touched the fields AI actually reads.
Firms that recognize the shift and ship accurate schema in 2026 are teaching the AI engines that they exist. Firms that do not stay filed under “no useful information” by systems that increasingly decide which firms get put in front of prospects. The gap is cheap to close and it widens every week it is left alone.
Where to Start
If the firm has not run a schema audit in the last six months, the 30-minute self-diagnostic above is the right first move. Paste the homepage and three recent blog post URLs into Google’s Rich Results Test. Read the Detected items. Run the three-question check. If the answers come back no, the work is already scoped for you.
Most boutique firms have schema deployed wrong, or not at all. Growth Engine PH audits the structured-data layer AI engines actually parse, rebuilds it across the seven types that matter, and configures the editorial fields (credentials, sameAs, partner profiles) that separate technically deployed from functionally visible. The audit is the first step. Talk to us about whether it fits your firm.
If the firm has already audited and you want the deeper diagnostic on why AI search routes prospects to directory listings instead of your site, the directory-routing companion post covers the mechanism end to end.
Frequently Asked Questions
What is schema markup and why does it matter for AI search?
Schema markup is a block of structured data inside your page’s HTML that declares to machines what the page is, who wrote it, what organization published it, and which external sources can verify the claim. For AI search engines like ChatGPT, Perplexity, and Google AI Overviews, this block is the primary way they parse and verify authority. A page with no schema, or with generic plugin-default schema, is harder for AI engines to attribute and less likely to be cited.
Do I need a developer to add schema markup to my WordPress site?
For most boutique professional services firms on WordPress, no. Plugins like Yoast SEO, Rank Math, and Schema Pro deploy the core schema types automatically. The editorial work, deciding which author Person, which credentials, which sameAs URLs to declare, is a configuration task that does not require code. Custom-built sites may need a one-time developer engagement, typically scoped at 4-8 hours.
Does schema markup directly affect Google rankings?
For Google’s classic organic search results, no. Google has consistently stated that structured data does not directly lift ranking position. That guidance is true and increasingly beside the point. AI Overviews, ChatGPT, Perplexity, and Claude rely on structured data as one input among several to decide which sources to cite in synthesized answers. The decision that matters in 2026 is AI citation, and AI citation runs on parseability.
What is sameAs and why is it the load-bearing field?
SameAs is a Schema.org property that holds an array of URLs pointing to external profiles representing the same entity. For an Organization, sameAs typically includes the LinkedIn company page, professional body directories, regulatory registry entries, and recognized industry indexes. For a Person, it includes their LinkedIn personal page, bar or CPA registration profile, and any professional body listing. AI engines follow these URLs to cross-reference the firm or person against external authority sources. Without sameAs, the schema makes a claim AI cannot verify; with sameAs, the schema offers AI a verification path.
How do I know if my current schema is plugin-default?
Run Google’s Rich Results Test on your homepage and read the Detected items output. If the Organization block has no sameAs array, or the Article block has no author Person nested with sameAs, the schema is plugin-default. Most boutique firms running Yoast or Rank Math with default settings produce exactly this pattern.
Should we deploy LocalBusiness or Organization schema?
LocalBusiness is the right variant for a single-office boutique with a public address. Multi-office firms, or firms without a fixed public address, typically use the broader Organization type. The difference is whether the firm declares itself as a local-presence entity (with address, opening hours, phone) or as a more general organization. For most international boutique professional services firms with a primary office plus remote partners, Organization is the cleaner default.
How long does it take to see AI citation results after fixing schema?
Typically 30-90 days. AI engines re-evaluate their citation sources on slower cycles than Google’s index, so a newly-correct schema deployment takes time to propagate. The lift is slower than a Google ranking change and more durable: once AI engines can parse the firm correctly, they keep being able to. The deployment compounds over months and quarters.
Is FAQPage schema worth deploying?
Yes, for pages with FAQ sections. AI engines cite FAQPage entries directly into AI Overview answers and ChatGPT responses when the user query matches the question. The rules: schema questions must match visible page questions verbatim, and answers must not be stuffed with marketing copy that does not appear in the visible page. Both shortcuts get caught and may trigger penalties. Deploy honestly.
What schema types should I skip?
The Schema.org vocabulary runs past 800 types covering 3D models, recipe nutrition data, dataset metadata, and many other categories irrelevant to a boutique professional services firm. The seven types in this post (Article, FAQPage, Organization or LocalBusiness, Person, Service, Review, BreadcrumbList) cover the parseability needs of every boutique law, accounting, or advisory consulting practice. Other types add complexity without proportionate benefit.
Will deploying schema mean I need to update everything every time Schema.org changes?
Probably not. The seven schema types relevant to professional services have been stable in the Schema.org vocabulary for years. Property additions happen at the edges (new optional fields), and deprecations are rare and well-signaled. The volatility argument applies to emerging schema types in narrow verticals, not to the seven this post recommends. A clean deployment in 2026 is likely to remain valid through 2027 and beyond.
By Mark Buraga, Independent SEO Consultant at Growth Engine PH. Last updated 2026-05-16.
Author page: Mark Buraga, Independent SEO Consultant, Growth Engine PH: /mark-buraga/
Internal links: directory-routing companion post | Talk to us