By Mark Buraga, Independent SEO Consultant at Growth Engine PH Last updated: 10 June 2026
Only 38 percent of the pages cited in Google AI Overviews still rank in the top 10 organic results (Ahrefs). Citation and ranking have come apart, which means a ranking audit can no longer tell you why you are not being cited. You need a different instrument.
You have probably done the obvious work already. Clean schema. Fast site. Genuinely helpful content. And the AI engines still will not name you. That gap is frustrating precisely because the page looks correct. But the reason a site is not cited is almost never one big thing. It is one of six specific blocks failing, in a specific order. Four of those blocks live on your page. Two live off it. And the two off-page blocks are the ones that actually decide whether you get cited.
This is the diagnostic I run, in the order I run it. Work through the six blocks, stop at the first one that fails, and you will almost always find the same thing: the page is ready to be cited, and nothing off the page is telling the engine it should be.
The 6-Block GEO Diagnostic, in one view

The 6-Block GEO Diagnostic audits citation failure in order: four on-page blocks (crawl access, render and parse, entity clarity, answer extractability) decide whether an engine can use you, and two off-page blocks (third-party validation, freshness and consensus) decide whether it will.
The order is not cosmetic. Each block depends on the ones before it. There is no point auditing whether your answers are extractable if the crawler cannot reach the page, and no point measuring your off-page validation if the engine cannot tell who you are. Run them top to bottom:
- Crawl Access – can an AI crawler reach the page?
- Render and Parse – is the content actually in the HTML it gets back?
- Entity Clarity – can the engine tell who is behind the page?
- Answer Extractability – is your answer in a form the engine can lift?
- Third-Party Validation – does anyone credible vouch for you?
- Freshness and Consensus – is the content current, covered, and named?
Blocks 1 through 4 are the work most people mean when they say “GEO.” Blocks 5 and 6 are where citation is actually won or lost, and they are the two almost nobody audits.
Block 1: Crawl Access
If an AI crawler is blocked in your robots.txt, your site is invisible to that engine no matter how good the content is.
Start at the most basic check because it is the most commonly missed. Open yourdomain.com/robots.txt and confirm the crawlers that feed AI answers are not disallowed: GPTBot and OAI-SearchBot (the ChatGPT crawlers), ClaudeBot, PerplexityBot, and Googlebot (which also feeds Google AI Overviews). A single Disallow rule aimed at any of them takes you out of that engine entirely.
The usual cause is not a deliberate block. It is a blanket rule someone added for an unrelated reason, or a security plugin that started filtering bots, quietly catching the AI crawlers in the same net. This block is deterministic and free to fix. It comes first because everything downstream is unmeasurable if the engine cannot fetch the page in the first place.
Block 2: Render and Parse
If your content or schema is injected by JavaScript, crawlers that do not execute JS never see it, so server-rendered HTML is the floor.
The crawler reached your page. Now the question is whether the content is actually in the HTML it received. Many sites render their important content, or their structured data, client-side with JavaScript. Some AI crawlers do not run JavaScript. If the substance only appears after the page executes, those engines get a blank.
The check takes a minute. View the raw page source rather than the inspector, and look for your key content and your schema in that raw HTML. If they are missing, they are invisible to a non-rendering crawler, no matter how perfectly they display in a browser. This is also where llms.txt fits, an emerging file that hands AI crawlers a curated map of your important pages. It is not yet honored everywhere, so its absence is never a penalty, but adding one is a cheap, forward-looking signal. The trap in this block is the phrase “but it is right there for users.” You are not optimizing for a user’s browser. You are optimizing for a fetch that may never render.
Block 3: Entity Clarity
AI engines cite verifiable entities, so if your site cannot prove who is behind it, it reads as a page published by nobody.
The first site I ever ran this full diagnostic on failed Block 3, and it was my own. Growth Engine PH passed every obvious check: fast, schema present, content shipping on schedule. Then its own rich-results test came back broken. The Organization name was wrong, there were zero sameAs links, and every post resolved to an empty author. To an AI engine, the site was a competent page published by nobody in particular. The fix was not more content. It was making the site a verifiable entity.
This is the block that turns a page into a source. Organization schema with sameAs links to five or more platforms, including the ones engines treat as identity anchors. A Person object for every author with a job title, an area of expertise, and their own sameAs links. A name, address, and contact detail that match everywhere they appear on the web. AI models lean heavily on entity graphs to decide whether a source is real, and a page from an entity they cannot verify is a risk they would rather route around. Schema is the substrate that does this work, which is exactly why it gets mistaken for the whole job.
Block 4: Answer Extractability
AI engines lift self-contained, fact-dense passages, so content that buries the answer in narrative is hard to cite even when it is correct.
Engines quote passages, not whole pages. The most citable passages are short, self-contained, and fact-led, running somewhere around 134 to 167 words in our own testing. They make sense pulled out of the page and dropped into an answer, with no surrounding paragraphs needed to decode them.
The practical move is to lead each section with the one-sentence answer, then support it underneath. If your answer only resolves after three paragraphs of windup, the engine has nothing clean to extract, and it will quote a competitor who wrote the same fact more directly. Structure and schema help the engine find the passage, but they do not write it. A perfectly marked-up page with the answer buried still fails this block. This is the on-page block that rewards editing more than tooling.
Block 5: Third-Party Validation
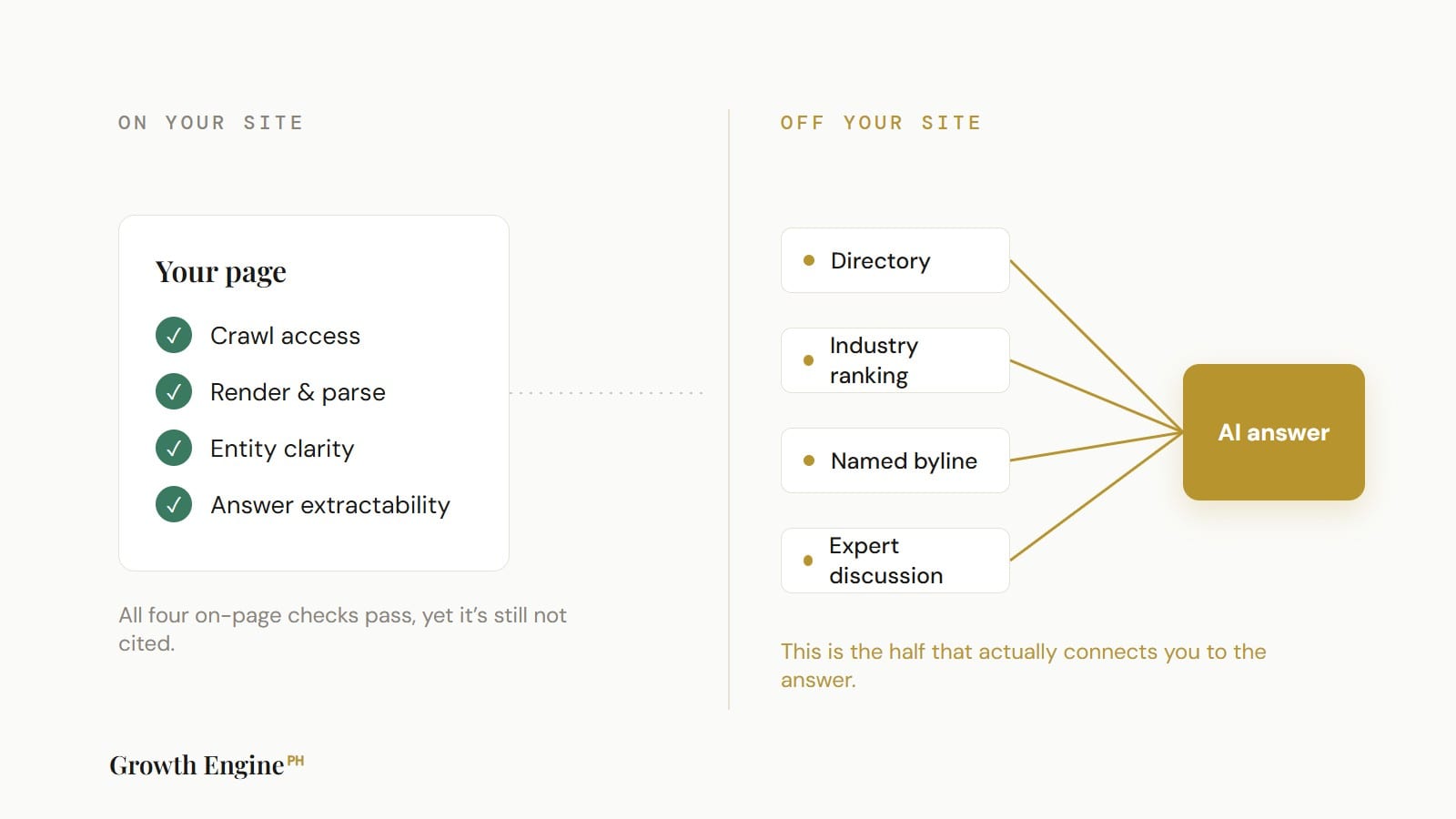
The citation decision is mostly made off your page: AI engines weight what credible third parties say about you across directories, rankings, named bylines, expert discussion, and video.
Here is where most audits stop one block too early. An AI engine answering a question does not just read your site. It cross-checks your claims against what independent sources say about you, across a short list of surfaces it preferentially trusts: editorially-overseen directories, independent industry rankings, named-byline publications, expert discussion platforms like Reddit and Quora, and credentialed video. I covered this in detail in how AI engines decide who to cite, because it is the single most underweighted layer in GEO work.
A page can pass blocks 1 through 4 flawlessly and still go uncited, because nothing credible vouches for it. This is also why directory-style queries so often get routed to aggregators instead of to the actual provider: the engine trusts the surface that has third-party validation over the one that does not. Block 5 is slower and harder to fix than anything on your page, which is precisely why it is worth the most. You cannot mark it up. You have to earn it.
Block 6: Freshness and Consensus
Being cited is structural, being mentioned by name is consensus, and stale or thinly-covered topics lose both.
The last block is two related signals. Freshness is whether the content is current and whether you actually cover the query space rather than touching it once. A genuine dateModified, real depth across a topic, and recency all feed how confidently an engine will surface you.
Consensus is the difference between a citation and a mention, and it is worth being precise about, the same way the AEO, GEO, and AIO acronyms describe different surfaces. A citation is a linked source the engine names in its references. A mention is your brand appearing inside the synthesized answer itself. Citations are earned structurally, through the first five blocks. Mentions are earned through market consensus, when enough credible places say the same thing about you that the engine treats it as fact. Thin coverage and a stale footprint cost you both.
How to run the diagnostic in an afternoon
Run the six blocks in order and stop at the first one that fails, because an earlier block failing makes the later blocks unmeasurable.
The order is the method. You cannot judge entity clarity if the crawler is blocked, and you cannot judge your validation surface if the engine cannot parse who you are. So go one through six, mark each block pass or fail, fix the first failure you hit, and re-check before moving on.
The pattern is remarkably consistent. Most sites pass blocks 1 through 4, or fix them inside an afternoon, because they are deterministic and largely on-page. Then the diagnostic stalls at 5 and 6, the off-page half, where the real gap almost always sits. That is not a content problem and it is not a markup problem. It is a validation problem, and the reason it feels slow to close is the same reason it is defensible once you do: nobody can buy it overnight, including the competitor outranking you.
If you are not being cited, you do not have a content problem. You have a block that is failing, and there are only six places to look. Run them in order. The page is rarely the reason. The two blocks off the page almost always are.
Engine Pro runs this diagnostic across all six blocks and rebuilds the off-page citation surface, the half most audits skip. If your AI visibility is not matching the work you have put in, let’s talk.
FAQs
Why isn’t my site cited by AI engines even though it ranks? Because ranking and citation have decoupled. Only 38 percent of AI Overview-cited pages also rank in the top 10, so a strong ranking no longer predicts a citation. The usual cause is an off-page validation gap (Block 5), not the page itself. The engine can see you fine, but nothing credible vouches for you.
How do I check if AI crawlers can reach my site? Open yourdomain.com/robots.txt and confirm GPTBot, OAI-SearchBot, ClaudeBot, PerplexityBot, and Googlebot are not blocked by a Disallow rule. A blanket disallow or an overzealous security plugin is the most common reason a site is invisible to a specific AI engine.
Does schema markup get me cited by AI? Schema helps an engine find your answer and verify your entity, but it does not create citations on its own. It points at the answer and proves who you are. If the off-page validation behind you is empty, clean schema still will not get you cited.
What’s the difference between an AI citation and an AI mention? A citation is a linked source the engine names in its references, earned structurally through retrievability and validation. A mention is your brand named inside the synthesized answer itself, earned through market consensus. They run on different mechanisms, which is why you can have one without the other.
How long should a citable passage be? Roughly 134 to 167 words, self-contained and fact-led. The most-cited passages make sense lifted straight out of the page, with the answer stated first and the support underneath, so an engine can quote them without pulling in the surrounding paragraphs.
Is GEO just technical SEO with new labels? The first two blocks, crawl access and render, overlap with technical SEO. The other four do not. Entity clarity, answer extractability, third-party validation, and the citation-versus-mention distinction are GEO-specific, and the last two are where citation is actually decided.